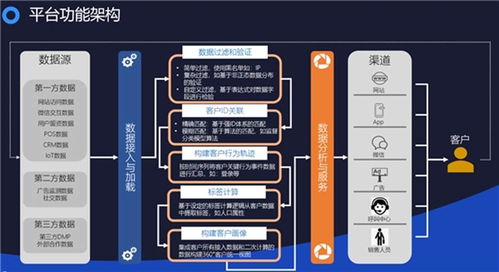
在數據驅動決策的時代,數據模型的治理已成為企業技術架構的核心環節。大淘寶作為國內領先的電商平臺,其數據規模龐大、業務場景復雜,數據模型治理的挑戰與重要性尤為突出。本文旨在分享大淘寶技術團隊在數據模型治理,特別是數據處理階段的階段性實踐經驗與思考。
一、數據處理的挑戰與目標
大淘寶的數據處理面臨多重挑戰:數據源多樣,包括用戶行為日志、交易記錄、商品信息、廣告投放等,格式不一、質量參差不齊;數據規模巨大,每日增量數據達到PB級別,對實時性與準確性要求極高;第三,業務需求快速迭代,數據模型需要靈活適應變化。因此,數據處理階段的核心目標在于:確保數據從采集到使用的全鏈路中,實現高效、準確、一致和可擴展的處理,為上層數據模型提供高質量的基礎。
二、階段性實踐:從原始數據到可信數據
在近期的治理工作中,大淘寶技術團隊聚焦數據處理的關鍵環節,采取了分階段的優化策略:
- 數據采集與接入標準化:統一了數據采集協議和接入規范,通過自研的日志采集工具和流式數據管道,實現了多源數據的實時匯聚。例如,針對用戶行為數據,建立了標準化的埋點體系,減少數據歧義和丟失。
- 數據清洗與質量監控:開發了自動化數據清洗框架,包括去重、糾錯、格式轉換等流程。引入實時質量監控系統,對數據完整性、一致性和時效性進行多維檢測,一旦發現異常,立即觸發告警和修復機制。這顯著提升了數據可信度,減少了因臟數據導致的模型偏差。
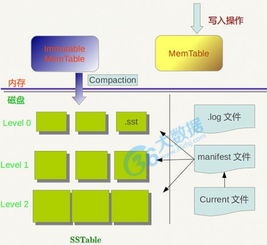
- 數據處理流水線優化:基于Flink和Spark等計算引擎,重構了批流一體的數據處理流水線。通過動態資源調度和計算優化,處理效率提升了約30%,同時降低了成本。團隊還探索了數據湖架構的應用,將原始數據與處理后的數據分層存儲,提高了數據復用性和靈活性。
- 元數據管理與血緣追蹤:建立了全面的元數據管理系統,記錄了數據從源頭到應用的完整血緣關系。這不僅幫助團隊快速定位數據問題,還支持影響分析,當上游數據變更時,能及時通知下游用戶,避免業務中斷。
三、成效與反思
通過階段性治理,大淘寶在數據處理方面取得了初步成效:數據質量指標(如準確率、及時率)平均提升了20%,數據處理延遲降低了50%,團隊協作效率因標準化而大幅提高。治理之路仍在繼續。反思當前實踐,我們認識到數據處理需與業務場景更緊密結合,例如,針對個性化推薦或風控等高頻場景,需進一步優化實時處理能力。隨著AI技術的融入,數據處理環節也開始探索智能化清洗和異常檢測,以應對未來更復雜的挑戰。
四、未來展望
大淘寶技術團隊將持續深化數據模型治理,特別是在數據處理階段,計劃推進以下方向:一是強化數據安全與隱私保護,在高效處理的同時確保合規;二是推動數據資產化,通過更精細的數據分層和標簽體系,提升數據價值;三是擁抱云原生和Serverless架構,實現彈性伸縮和成本優化。我們相信,通過持續的治理創新,數據處理將為淘寶生態的智能進化奠定更堅實的基礎。
數據處理是數據模型治理的基石。大淘寶的階段性分享表明,只有夯實數據處理環節,才能構建出可靠、高效的數據模型,最終驅動業務增長與用戶體驗提升。這條路雖充滿挑戰,但每一步都值得深耕。